
Advanced anomaly detection: Machine learning (ML) approaches
An Intrusion Detection System (IDS) is a security technology or tool that monitors and analyzes network traffic or system activities to identify and respond to potential security threats or suspicious behavior. It acts as a vigilant guardian, continuously scanning and evaluating data to detect unauthorized access, attacks, anomalies, or policy violations within a network or a computing environment. 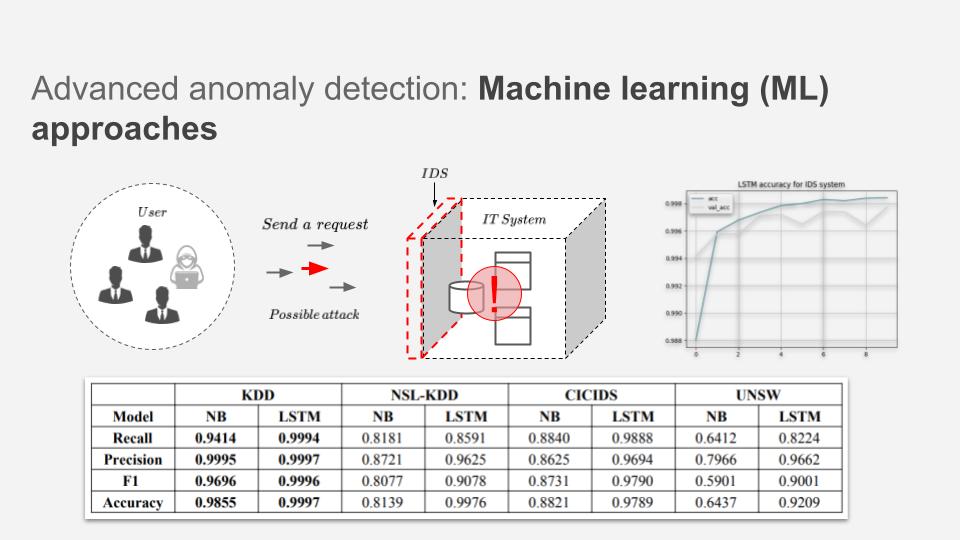
In this project, “Advanced anomaly detection: Machine learning (ML) approaches” serves as a comprehensive study aimed at identifying the most effective model for anomaly detection. The study focuses on evaluating and comparing various machine learning models to ascertain their performance in detecting anomalies within different datasets, including the KDD cup, CICIDS, UNSW-NB15, and NLS-KDD. Through rigorous experimentation and analysis, we aim to determine the model that exhibits the highest accuracy, sensitivity, and specificity in identifying anomalous patterns within each dataset. This approach involves fine-tuning the models, optimizing hyperparameters, and utilizing state-of-the-art techniques to ensure a robust and reliable anomaly detection system across diverse datasets.
Datasets
UNSW_NB15 Dataset
The UNSW-NB15 dataset is a widely recognized and extensively used dataset in the realm of Intrusion Detection Systems (IDS). It was created by researchers at the University of New South Wales (UNSW) to facilitate the development and evaluation of intrusion detection algorithms and techniques. The dataset is a comprehensive collection of network traffic data captured in a controlled lab environment, simulating a realistic network scenario. It includes various types of network traffic, such as normal and malicious activities, which are essential for training and testing IDS algorithms. The UNSW-NB15 dataset is labeled, providing ground truth information about different types of network attacks, making it a valuable resource for benchmarking the performance of intrusion detection models. Researchers and practitioners often utilize this dataset to analyze, research, and design effective IDS solutions, aiming to enhance network security and thwart potential cyber threats. 
NSL-KDD
The NSL-KDD (National Science Foundation for the State of Kerala, Knowledge Discovery in Databases) dataset is another notable and widely used dataset in the field of Intrusion Detection Systems (IDS). It was created as an improvement over the original KDD Cup 1999 dataset, addressing certain shortcomings and challenges presented by the latter. The NSL-KDD dataset comprises network traffic data collected from a simulated computer network environment, mimicking various network attacks and normal activities. 
CICIDS 2017
The CICIDS 2017 (Canadian Institute for Cybersecurity Intrusion Detection Systems) dataset is a significant and comprehensive dataset widely utilized in the domain of Intrusion Detection Systems (IDS). It was created by the Canadian Institute for Cybersecurity to support research and analysis related to network security and intrusion detection. The dataset comprises network traffic data collected from a realistic and diverse network environment, including both benign and malicious activities. 
KDD Cup 1999
The KDD Cup 1999 dataset is a pioneer and landmark dataset in the field of Intrusion Detection Systems (IDS). It was used as part of the Third International Knowledge Discovery and Data Mining Tools Competition (KDD Cup) in 1999. This dataset was derived from network traffic data and simulated a computer network environment, primarily focusing on intrusion detection and cybersecurity. 
Implementation
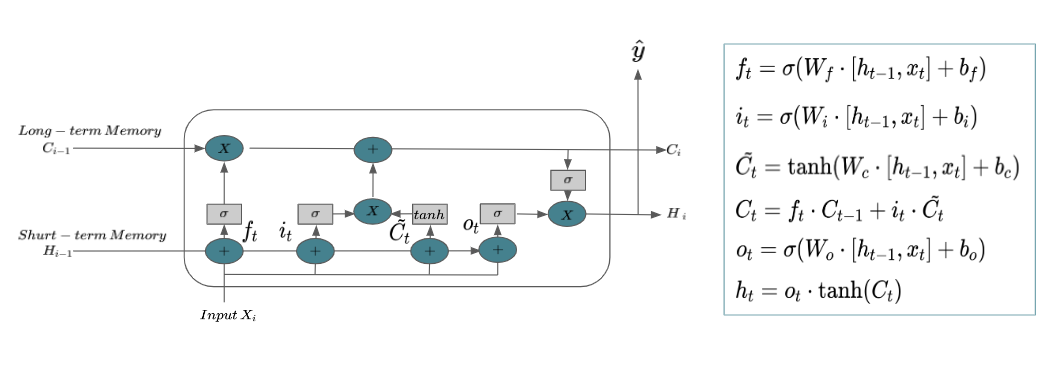
In this project, we employ the Naive Bayes classification algorithm to categorize data effectively. Naive Bayes is a probabilistic algorithm based on Bayes’ theorem, assuming independence among features. We preprocess and prepare the datasets, extracting relevant features and organizing them into distinct classes. Utilizing the Naive Bayes approach, we calculate the conditional probabilities of each feature given a particular class, enabling the algorithm to make predictions based on the highest probability. By training the Naive Bayes classifier on labeled data from datasets like KDD cup, CICIDS, UNSW-NB15, and NLS-KDD, we strive to achieve accurate and efficient classification results, aiding in various applications such as intrusion detection, network security, and anomaly identification.
Result
In the analysis of the results obtained from the conducted experiments, it is evident from the table below that both LSTM and Naive Bayes algorithms produced the most promising results in the context of the KDD Cup 99 dataset. The comparison shows that LSTM outperformed Naive Bayes in terms of accuracy.

In the case of the KDD Cup 99 dataset, LSTM exhibited exceptional performance, achieving an accuracy of 99.97%, showcasing its capability to effectively model and classify the given data. On the other hand, Naive Bayes, while still performing admirably, fell slightly behind LSTM with an accuracy of 98.55 However, the results were notably different for the UNSW-NB15 dataset. Here, LSTM maintained a respectable accuracy of 92.09%, indicating its adaptability and robustness across different datasets. On the other hand, Naive Bayes displayed a lower accuracy of 64.37% for this dataset, suggesting that it might not be the best choice for this particular dataset in comparison to LSTM.
In summary, LSTM emerged as the superior algorithm, providing the most accurate predictions in both datasets, showcasing its potential for effective anomaly detection and classification. Naive Bayes, while still competent, demonstrated variability in performance depending on the dataset, highlighting the need for careful algorithm selection based on the specific dataset characteristics. 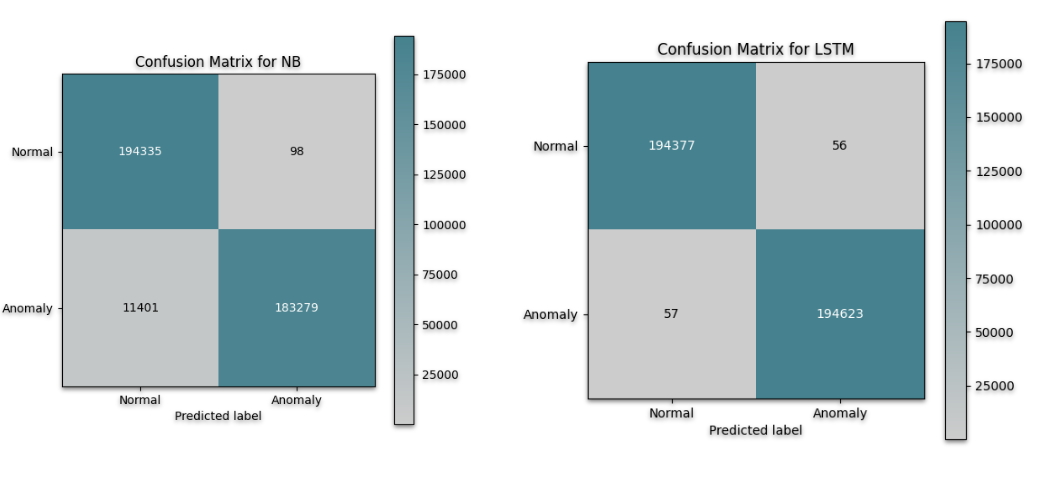
Github Url Project: /jboussouf/Advanced-anomaly-detection-Machine-learning-approaches