
Advancing Diabetic Retinopathy Detection: Fine-Tuning VIT Models
This work focuses on advancing the detection of diabetic retinopathy through the implementation of Vision Transformer (ViT) models, a state-of-the-art deep learning approach to computer vision. The system automates the identification of levels of diabetic retinopathy by classifying retinal images into three categories. The ViT model is meticulously trained on a large dataset of retinal images from Kaggle (available at amanneo/diabetic-retinopathy-resized-arranged).
Data PreProcessing
In order to simplify the classification task and streamline the analysis process, the original dataset, consisting of five classes based on the severity of diabetic retinopathy, has been transformed into three classes. The new class structure is as follows:
- 0 - No DR : This class remains unchanged and represents images of eyes without any signs of diabetic retinopathy
- 1 - Mild : This class combines the original "Mild" and "Moderate" classes. Images in this class exhibit mild to moderate signs of diabetic retinopathy, representing the initial and intermediate stages of the condition
- 2 - Proliferative : This class combines the original "Severe" and "Proliferative DR" classes. Images in this class depict severe manifestations of diabetic retinopathy, indicating an advanced stage of the disease and the potential for vision loss.
Distribution of the Dataset after compression: 
Fine-Tune VIT for Diabetic Retinopathy problem
Fine-tuning is a powerful technique in machine learning that involves taking a pre-trained model and adapting it to a specific task or dataset. It is particularly useful when working with limited labeled data or when aiming to achieve high performance on a specialized task. The process of fine-tuning typically involves two main steps : initializing the pre-trained model with its learned weights and then updating these weights by training on the new task-specific dataset.
VIT Result
During the fine-tuning process of the Vision Transformer (VIT) model for Diabetic Retinopathy, we observed a remarkable trend in the history of loss. As the model iteratively learned from the task-specific dataset, the loss consistently decreased with each training epoch. This decline in loss indicates that the model successfully minimized the difference between its predicted outputs and the ground truth labels, moving closer to accurate predictions.
Loss of VIT fine-tuning: 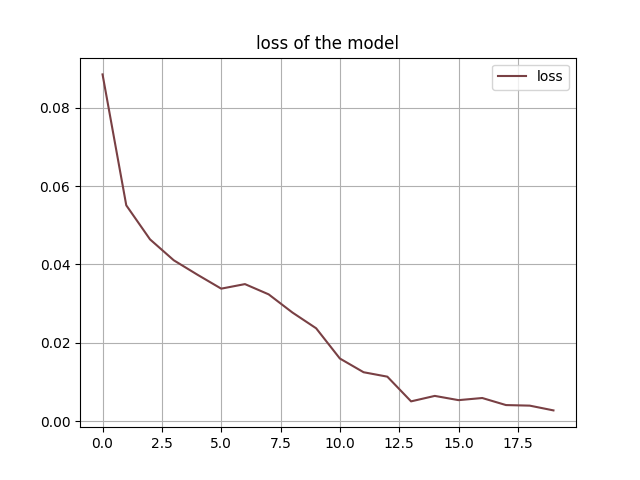
The fine-tuned Vision Transformer (VIT) model exhibited an exceptional performance during training, as evident from the history of accuracy. Throughout the training process, the model consistently achieved an accuracy of over 97% on the task-specific dataset. This high accuracy was a testament to the efficacy of fine-tuning and the ability of the VIT model to discern relevant features for Diabetic Retinopathy classification. The consistently high accuracy demonstrated the model’s robustness and generalization capabilities, implying that it could accurately classify unseen retinal images with a high level of confidence.
Accuracy of VIT fine-tuning: 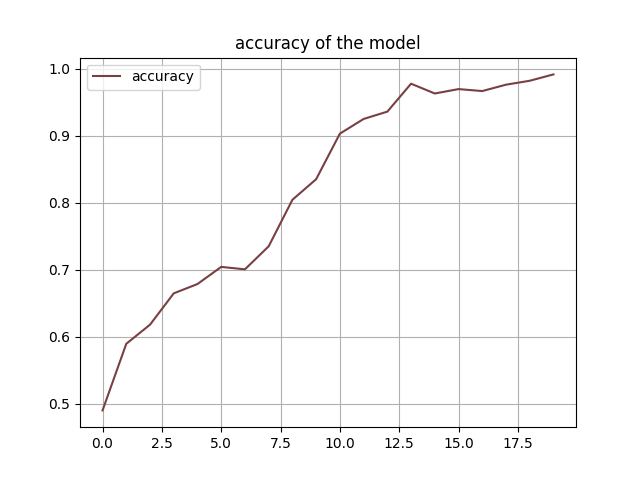
After fine-tuning the Vision Transformer (VIT) model for Diabetic Retinopathy, we evaluated its performance on an independent testing dataset. The confusion matrix provided a comprehensive breakdown of the model’s predictions across different severity classes of Diabetic Retinopathy. It revealed the distribution of true positive, true negative, false positive, and false negative predictions, allowing us to assess the model’s performance comprehensively. By examining the confusion matrix, we could identify potential areas of misclassification and gain insights into the model’s strengths and weaknesses. The confusion matrix acted as a valuable diagnostic tool, guiding us in further fine-tuning the model to optimize its accuracy and specificity for different severity levels.
Confusion Matrix on Test dataset using VIT: 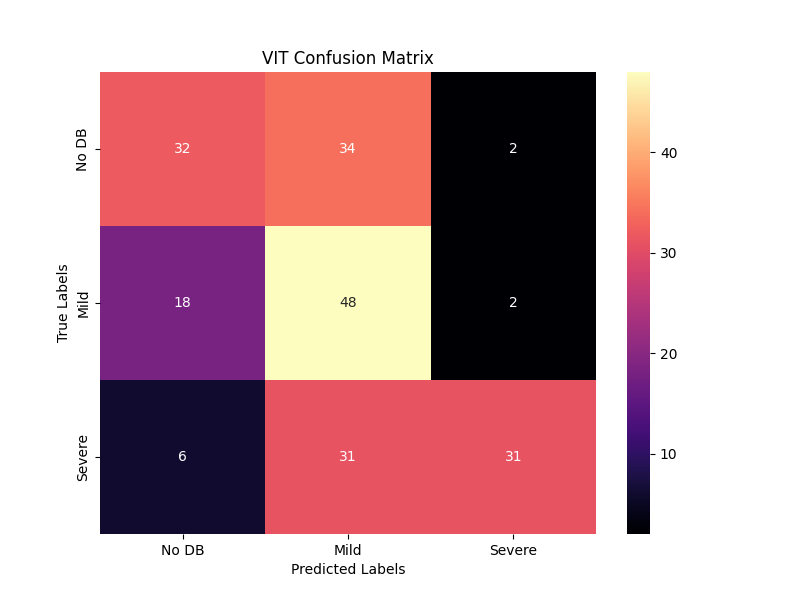
Model Deployment
The model is integrated into a web application using Flask as the web framework. Flask facilitates handling HTTP requests and responses, providing a smooth communication channel between the front-end and back-end components. The front-end of the application is developed using web technologies such as HTML, CSS, and JS.
The web application interface consists of a user-friendly layout with two distinct zones dedicated to image selections : the “Right” and “Left” eye image zones. The design prioritizes simplicity and intuitiveness, allowing users to effortlessly upload or choose images for each eye.
Once the user clicks on the “Predict” button, the web application initiates the image uploading process, securely transferring the selected “Right” and “Left” eye images to the server for analysis. The server, equipped with powerful image processing VIT_fine_tuned model, Once the prediction process is complete, the web application redirects the user to a new page displaying the results.
The “Prediction Page” is designed to showcase the uploaded images alongside the insightful predictions made by the VIT model. The predictions are presented in an easily interpretable format, such as a labeled classification result or a confidence score for each image. Additionally, visual representations like heatmaps or highlighted areas further assist the user in understanding how the model arrived at its conclusions.
Web_App interface: 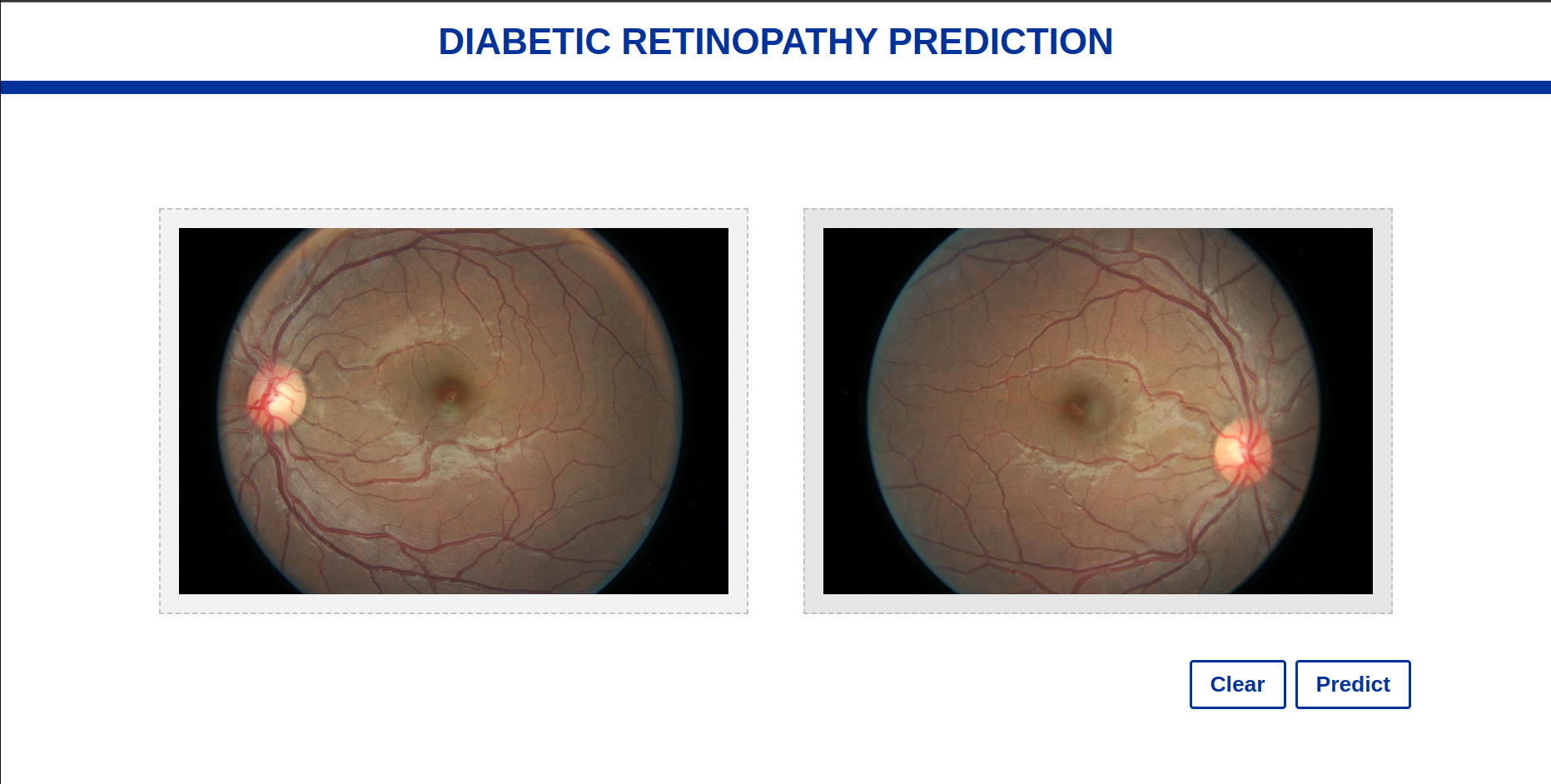
Results of the Model: 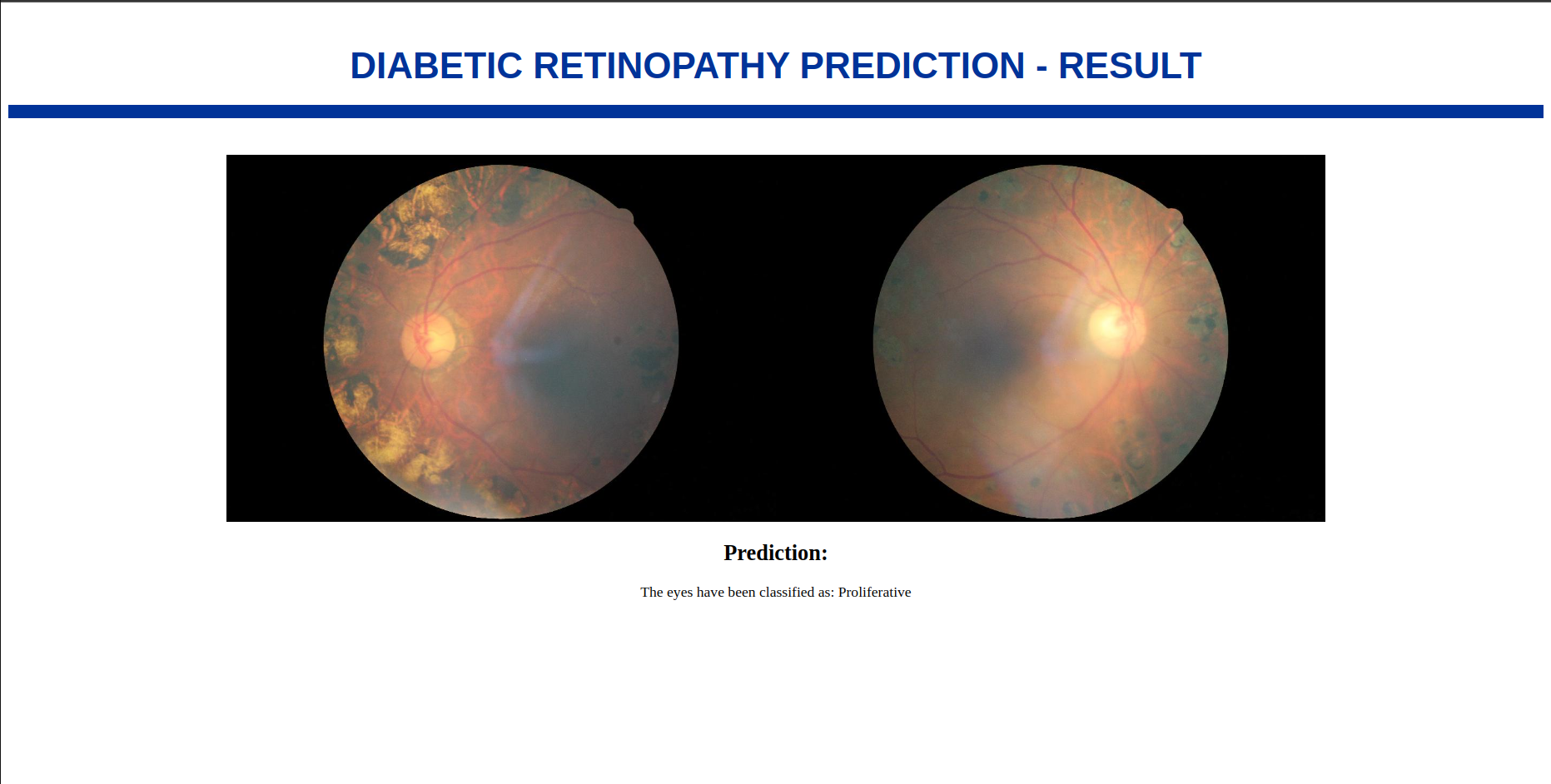
Important Note : If the subtraction between the predicted results for the “Right” and “Left” eye images yields a percentage of evaluation that is under 0.1 (i.e., less than 10% difference), the user will receive the following message : “We hope that you will see a specialized ophthalmologist due to the inability of the model to extract sufficient information”.
The note in case of eval1 - eval2 < 0.1:
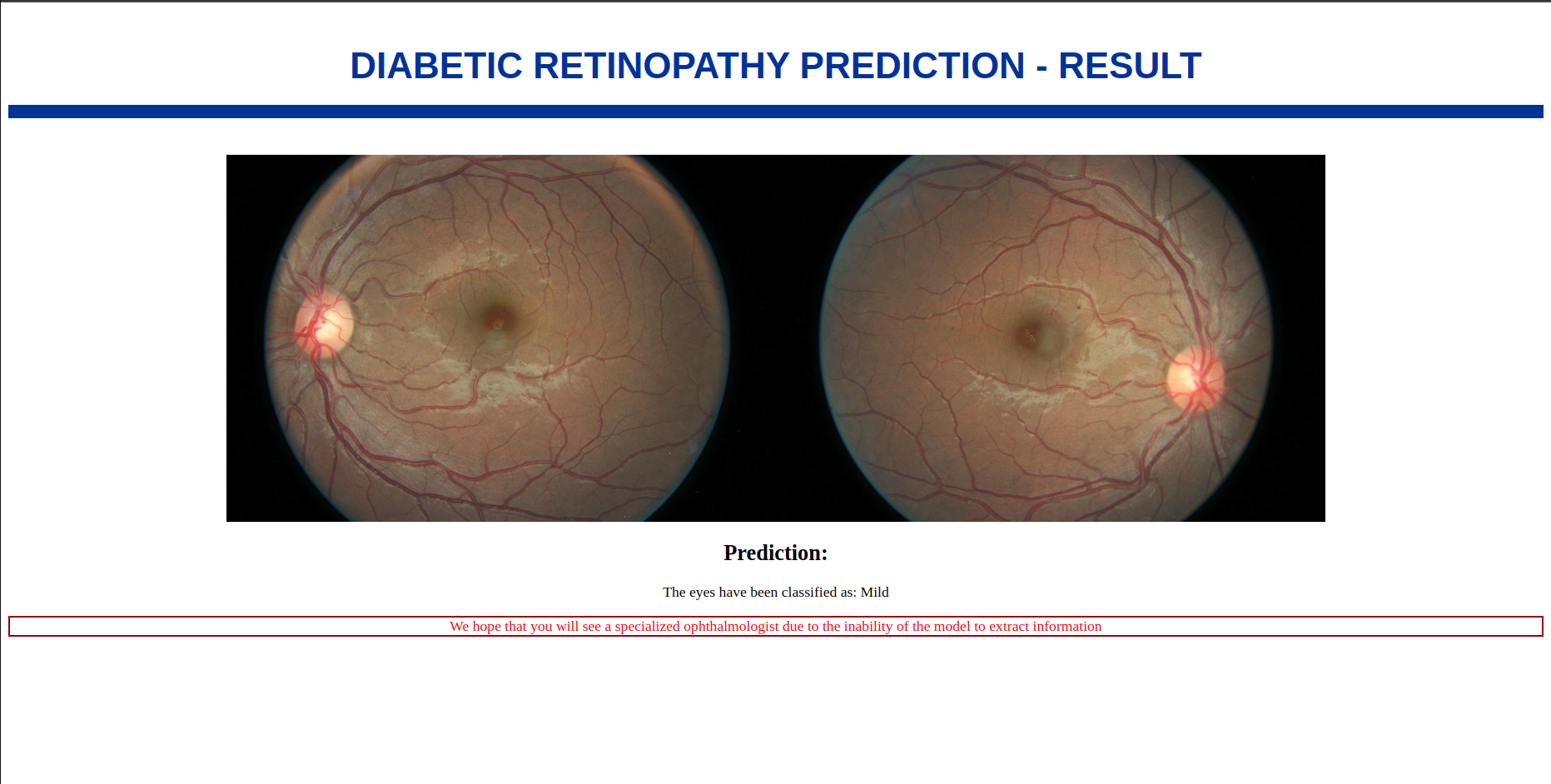
Concludion
In conclusion, the fine-tuning process of the VIT model for Diabetic Retinopathy yielded impressive results. The history of loss consistently decreasing to 0.0005 demonstrated the model’s effective learning and ability to capture essential visual features specific to the task. Moreover, the history of accuracy consistently surpassing 0.97 showcased the model’s remarkable generalization and high-level performance. Finally, the confusion matrix on the testing dataset provided a detailed analysis of the model’s predictions, allowing for the identification of potential areas for improvement. Altogether, these results indicate the immense potential of the fine-tuned VIT model in aiding the medical community with accurate and reliable Diabetic Retinopathy diagnosis.
Project URL on github: Advancing Diabetic Retinopathy Detection: Fine-Tuning VIT Models