
Overcoming Speech Recognition Challenges with GAN based Solutions
This study applies deep learning techniques to improve speech recognition in different environments, including noisy situations. The study presents the results of a Convolutional Neural Network (CNN) model that achieved high accuracy in recognizing spoken words in clean audio data but struggled as noise levels increased. An attempt to use a simple autoencoder to remove noise from the audio data resulted in a significant decline in classification performance, indicating the need for more advanced denoising techniques. The study proposes the Speech enhancement Generative Adversarial Network (SEGAN) as a solution to improve speech recognition’s robustness by generating clean speech signals from noisy inputs. The results demonstrate the potential of deep learning techniques in improving speech recognition technology, but careful evaluation of various components and techniques is crucial for optimal performance.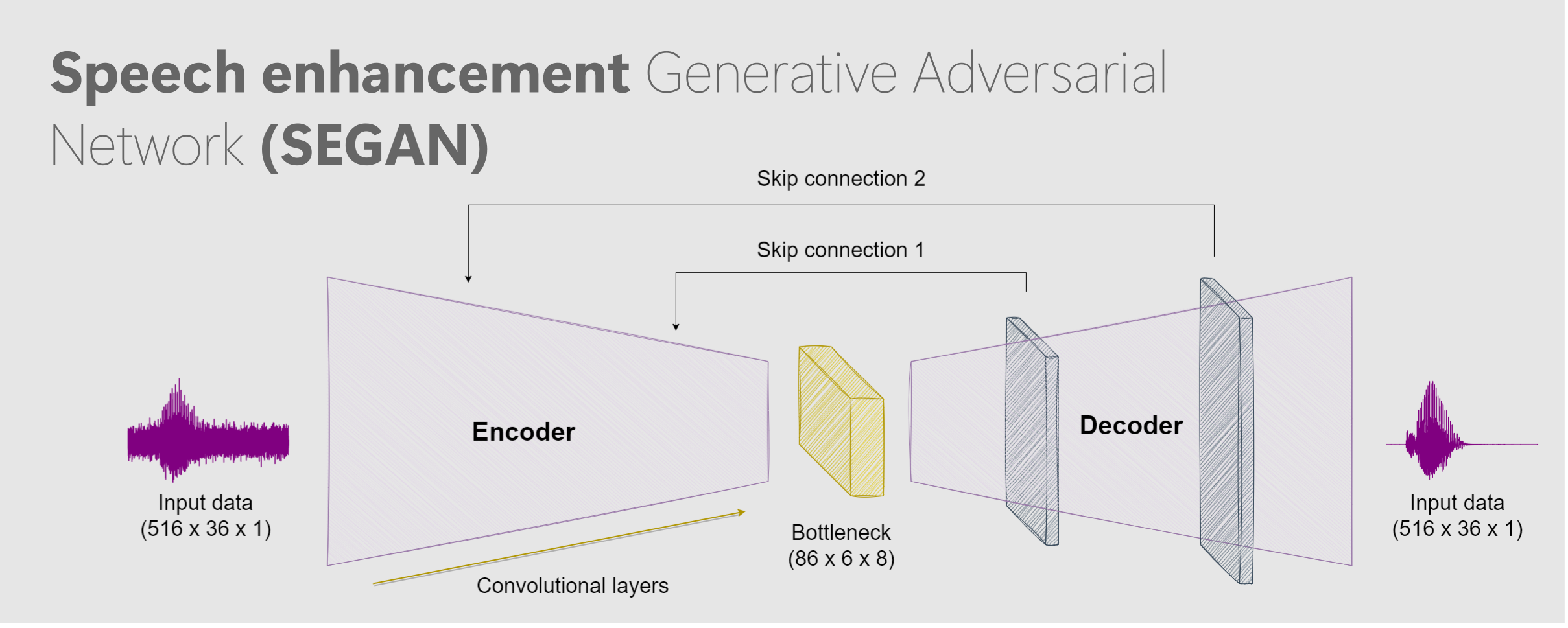
Data Presentation
In this project, we introduce a meticulously curated dataset that serves as the backbone for tackling the Speech Recognition Challenges using GAN-based solutions. The dataset comprises WAV audio files, each precisely one second in length, making it a perfect fit for training and evaluating speech recognition models. Our carefully selected dataset is sourced from Kaggle and is openly available to the research community at the following URL: wangshaoqi/speech-commands.
This dataset is a valuable resource for anyone looking to delve into the fascinating domain of speech recognition and explore the potential of Generative Adversarial Networks (GANs) for enhancing speech processing systems. With diverse audio samples representing various speech commands, our dataset promises to foster innovative and robust advancements in the field of automatic speech recognition.
In this project, we have chosen to work with just three words: “one,” “two,” and “three.” These carefully selected words represent essential phonetic elements and will simplify the initial stages of training and evaluation.
Data Transformation
In addition to transforming the audio data into spectrogram format, we will augment the dataset by introducing random noise at different levels. Data augmentation is a powerful technique that helps improve the robustness and generalization of our models. By injecting random noise into the audio samples at varying intensities, we simulate real-world environmental factors and add variability to the training data. This approach allows our models to become more resilient to noise and other distortions commonly encountered in practical speech recognition scenarios.
Spectrogram format of bowth data with noise and without noise: 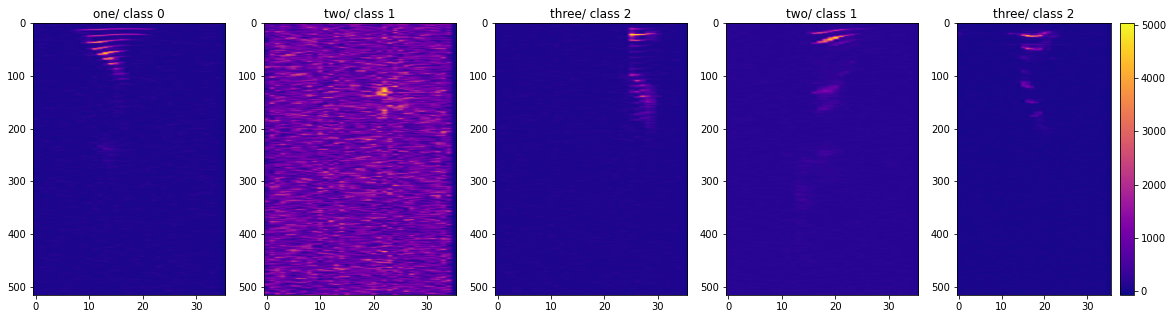
Classification Model
For our speech recognition task, we employed a Convolutional Neural Network (CNN) architecture. The model architecture consists of multiple convolutional layers, each followed by max-pooling layers to downsample the spatial dimensions of the feature maps. The first two convolutional layers have 128 filters, while the subsequent two have 64 filters. The final convolutional layer has 32 filters before flattening the output to connect to a fully connected (dense) layer with three neurons, representing the three target classes “one,” “two,” and “three.” The model has a total of 543,747 trainable parameters, making it an efficient choice for our speech recognition task. By training this CNN architecture on the transformed spectrogram data enriched with random noise, we aim to develop robust GAN-based solutions for accurate and efficient speech recognition.
CNN architecture: 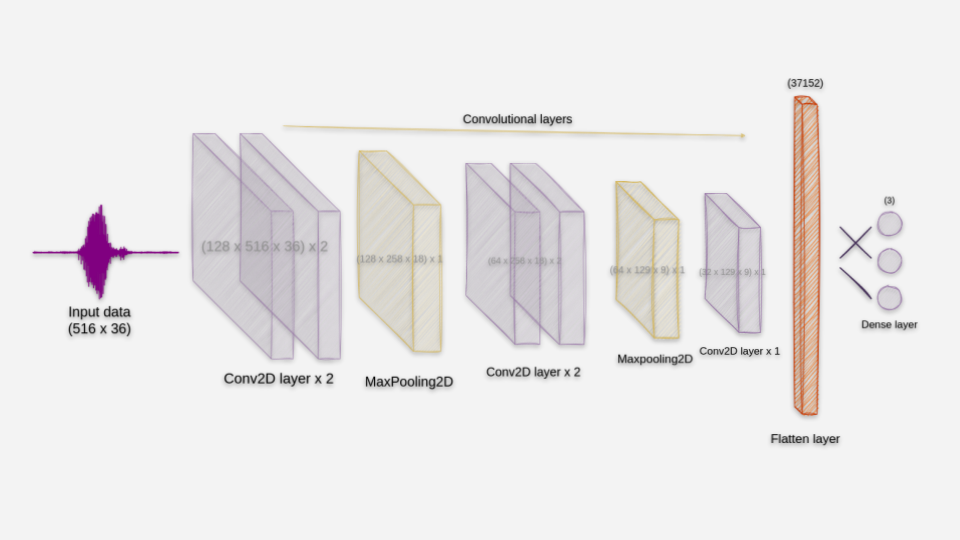
The loss nad accuracy of the CNN Model:
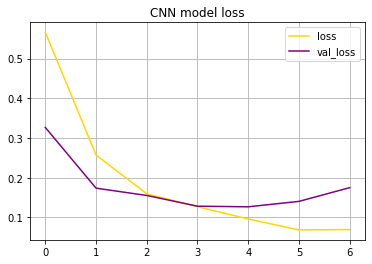
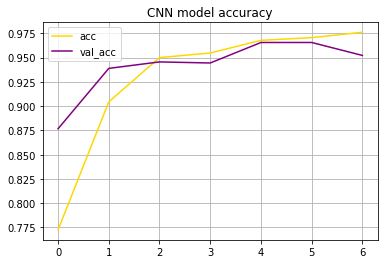
CNN Evaluation
when we systematically introduce noise effects to the data during testing, we observe a decline in the model’s performance. The noise, which can be in the form of random perturbations, distortions, or other modifications to the data, adversely affects the CNN’s ability to discern meaningful patterns and features in the input. As a result, the accuracy and overall effectiveness of the model in classifying the data diminish, leading to lower evaluation scores on the performance chart. This highlights the sensitivity of the CNN to noise and underscores the need for robustness and noise-resistant techniques in real-world applications.
CNN Evaluation: 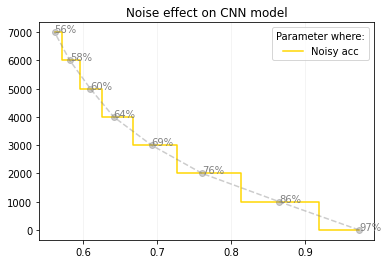
Autoencoder
We employ an autoencoder architecture based on a Convolutional Neural Network (CNN) with a two-part structure, consisting of an encoder and a decoder, seamlessly connected through a bottleneck layer. The encoder efficiently compresses the input data into a lower-dimensional representation, while the decoder reconstructs the original data from this compressed representation. By leveraging the bottleneck layer, we ensure that only the most salient features are preserved, leading to more effective feature extraction. Additionally, we introduce skip connections between convolutional layers to facilitate the flow of information from earlier layers to later ones.
Autoencoder architect: 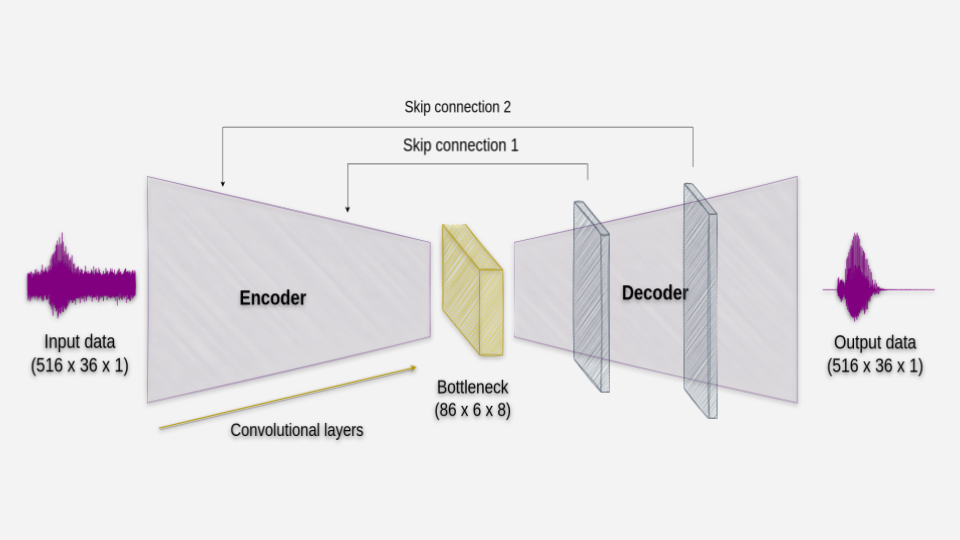
Autoencoder results
When employing autoencoders, a type of neural network used for unsupervised learning and data compression, suboptimal outcomes may arise if the generated data lacks clarity. This deficiency in clarity could lead to a diminished reconstruction quality of the original input samples, thereby adversely affecting subsequent tasks. In contrast, Convolutional Neural Networks (CNNs) tend to yield superior results in such situations.
Autoencoder results: 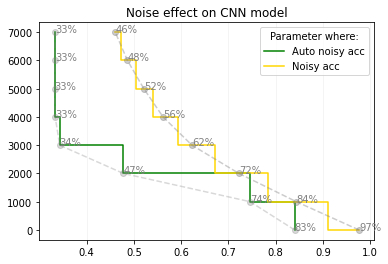
SEGAN architecture
In the GAN architecture, three main components play crucial roles. Firstly, an autoencoder is incorporated into our architecture to serve as the generator. Its purpose is to attempt noise removal from the audios, refining the data for subsequent stages. Secondly, the discriminator comes into play, responsible for distinguishing between the generated data and real data. It evaluates the input and provides a verdict on whether the data is authentic or counterfeit. Finally, the dataset serves as the third essential element, utilized by the discriminator to make accurate judgments regarding the authenticity of the data, ultimately shaping the overall performance and effectiveness of the GAN model.
SEGAN architect: 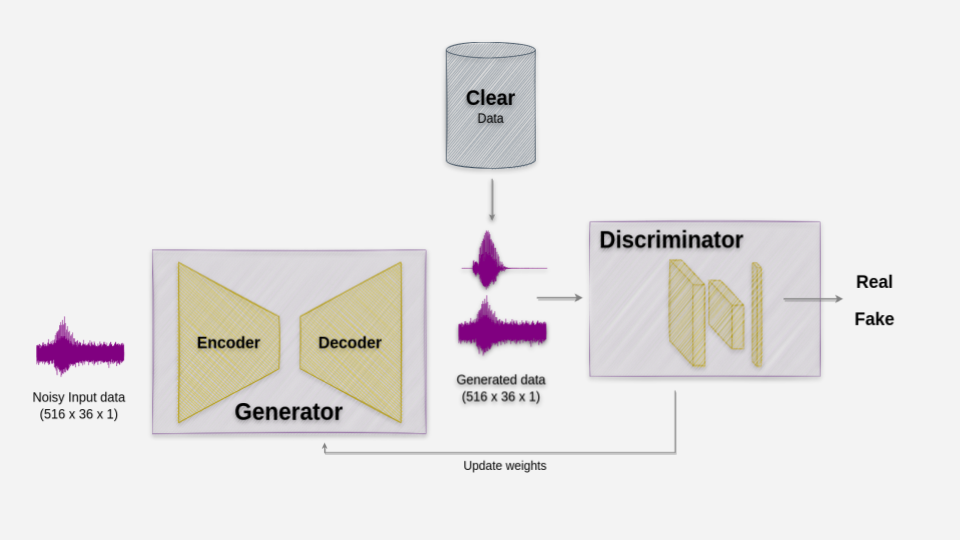
SEGAN results
In the process of model evaluation, the effectiveness of the autoencoder trained within the GAN architecture becomes evident from the following figure. Notably, when subjected to 5000 units of noise, the CNN model achieves a modest accuracy of 40%. However, upon utilizing the Autoencoder to remove the noise from the data, its performance improves significantly to a commendable 60%. It is worth noting that the CNN model outperforms the Autoencoder in scenarios where no noise is applied, achieving an impressive accuracy of 82%, while the Autoencoder yields a respectable 75%. This comparative analysis underscores the autoencoder’s capability in noise reduction, thereby enhancing the CNN model’s accuracy in the presence of noise, while also highlighting the CNN’s inherent strength in noise-free conditions.
SEGAN results: 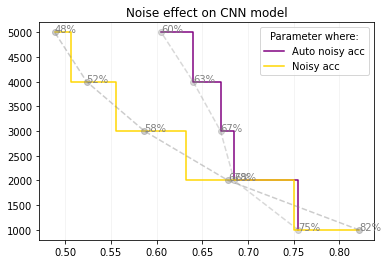
Project URL on github: jboussouf/Overcoming-Speech-Recognition-Challenges-with-GAN-based-Solutions